


Data Quality Assessment (DQA) is the process of evaluating data to determine whether it is accurate, complete, and reliable enough to support specific business decisions. High-quality data is essential for making informed decisions, developing effective strategies, and driving innovation within organizations.
This article provides a practical, end-to-end guide to Data Quality Assessment. It covers core definitions, proven techniques, industry standards, and step-by-step assessment practices, with a strong focus on what delivers the most business value in real-world environments.
Data Quality Assessment Overview
Data Quality Assessment (DQA) is a critical process that evaluates the quality of data to ensure its suitability for decision-making. It involves examining the data to identify its strengths and weaknesses, laying the groundwork for enhancing its quality.
This process includes various analyses, from basic accuracy checks to more complex evaluations of consistency, aiming to ensure data is reliable and valuable.
Key Components of Data Quality
-
Accuracy: This measures how precisely data reflects the real-world entities or events it is intended to represent. High accuracy means the data is correct and free from errors.
-
Completeness: Completeness assesses whether all required data is available. Incomplete data can lead to gaps in analysis and decision-making.
-
Consistency: Consistency ensures that data is uniform across different datasets and systems. Inconsistent data can lead to confusion and incorrect conclusions.
-
Validity: This component checks if the data conforms to the defined rules and formats. Valid data adheres to the business rules and constraints set for the dataset.
-
Timeliness: Timeliness measures whether data is up-to-date and available when needed. Outdated data can be irrelevant and misleading.
-
Uniqueness: Uniqueness ensures that each record in a dataset is distinct and not duplicated. Duplicate records can distort analysis and lead to inaccurate results.
-
Integrity: Integrity checks the correctness of the relationships between data elements. For example, in a database, referential integrity ensures that foreign keys correctly correspond to primary keys.
-
Reliability: Reliability assesses whether data can be consistently trusted over time. Reliable data maintains its accuracy and consistency through various processes and usage.
-
Relevance: Relevance ensures the data is appropriate and useful for the intended purpose. Irrelevant data can clutter systems and impede effective analysis.
In practice, not all dimensions carry equal weight. The importance of accuracy, timeliness, or completeness depends on how the data is used. For example, analytical reporting may tolerate minor delays, while operational or automated systems often fail if data is late or inconsistent. Effective DQAs prioritize dimensions based on business risk rather than theoretical completeness.
Common Data Quality Standards for Ensuring High Data Integrity
ISO 8000
ISO 8000 is an international standard that sets the benchmark for managing information quality. It encompasses requirements for defining, measuring, and enhancing data quality. This standard focuses on ensuring data accuracy and interoperability across different systems and organizational boundaries.
By adopting ISO 8000, organizations can maintain high data quality, which is crucial for making well-informed decisions. ISO 8000 provides a comprehensive framework that helps organizations identify data issues early and implement corrective measures efficiently.
DAMA-DMBOK Guidelines
The Data Management Association (DAMA) developed the Data Management Body of Knowledge (DMBOK) to serve as an extensive guide to data management practices.
Within DMBOK, the guidelines for data quality outline best practices and processes for effective data governance. These guidelines are essential for establishing robust data governance procedures.
Adopting DAMA-DMBOK guidelines ensures a shared understanding of data quality standards across an organization, promoting consistency and reliability in data handling. These guidelines help in creating a culture of continuous improvement in data quality.
CMMI-DQ Model
The Capability Maturity Model Integration for Data Quality (CMMI-DQ) provides a detailed and practical approach to assessing and improving data quality management. This model helps organizations evaluate their current data quality processes and guides them toward achieving higher levels of maturity.
Implementing the CMMI-DQ model allows organizations to systematically enhance their data quality, leading to more reliable and trustworthy data. The CMMI-DQ model not only improves data quality but also aligns data management practices with organizational goals, thereby enhancing overall efficiency and effectiveness.
Meeting data quality standards is a commitment to excellence, providing a foundation for trust and confidence in the data we use and share.
Techniques for Assessing Data Quality
1. Data Profiling
Data profiling involves a detailed examination of data to understand its structure, content, and relationships. This process identifies patterns, anomalies, and irregularities that can reveal deeper quality issues.
Advanced data profiling techniques use algorithms to detect outliers and inconsistencies, providing a clear picture of data health. Data profiling is most effective when used early and repeatedly, especially in environments with frequent schema changes or multiple upstream sources. It provides fast insight but should be complemented with downstream checks to avoid a false sense of data health.
2. Data Auditing
Data auditing evaluates data against predefined rules and criteria to identify deviations and errors. This technique includes checks for data integrity, accuracy, and compliance with standards.
Automated auditing tools can scan large datasets efficiently, uncovering hidden errors that manual reviews might miss. Implementing regular data audits ensures continuous monitoring and maintenance of data quality.
3. Statistical Analysis
Statistical analysis applies mathematical methods to assess and improve data quality. Techniques such as regression analysis, hypothesis testing, and variance analysis help quantify the extent of data quality issues.
These methods can identify patterns that indicate systemic problems, allowing organizations to address root causes effectively. Statistical analysis provides a quantitative foundation for data quality initiatives.
Statistical techniques are most valuable when data volumes are large or when quality issues are subtle and systemic. However, for small or highly structured datasets, they can add unnecessary complexity. Mature DQA programs apply statistical analysis selectively, where it meaningfully improves detection rather than as a default step.
4. Rule-Based Validation
Rule-based validation checks data against specific business rules and constraints to ensure compliance. This method involves setting up validation rules that data entries must meet, like format requirements and logical consistency checks.
Advanced rule-based systems can handle complex validation scenarios, ensuring high levels of data integrity and consistency. Regular rule-based validation prevents errors from entering the wider ecosystem.
5. Data Cleansing
Data cleansing is the process of correcting or removing inaccurate, incomplete, or irrelevant data. This involves identifying and rectifying errors, eliminating duplicates, and filling in missing information.
Advanced data cleansing tools use machine learning to automate corrections and enhance accuracy. Effective data cleansing transforms raw data into a reliable asset, essential for accurate analysis and reporting.
One of the most frustrating realities of poor data quality is how much time it wastes for data professionals. Surveys consistently show that data scientists and analysts spend the majority of their time not on insightful analysis or modeling, but on preparatory work dominated by cleaning and organizing data.
Figure: Time Spent by Data Scientists/Analysts on Key Tasks
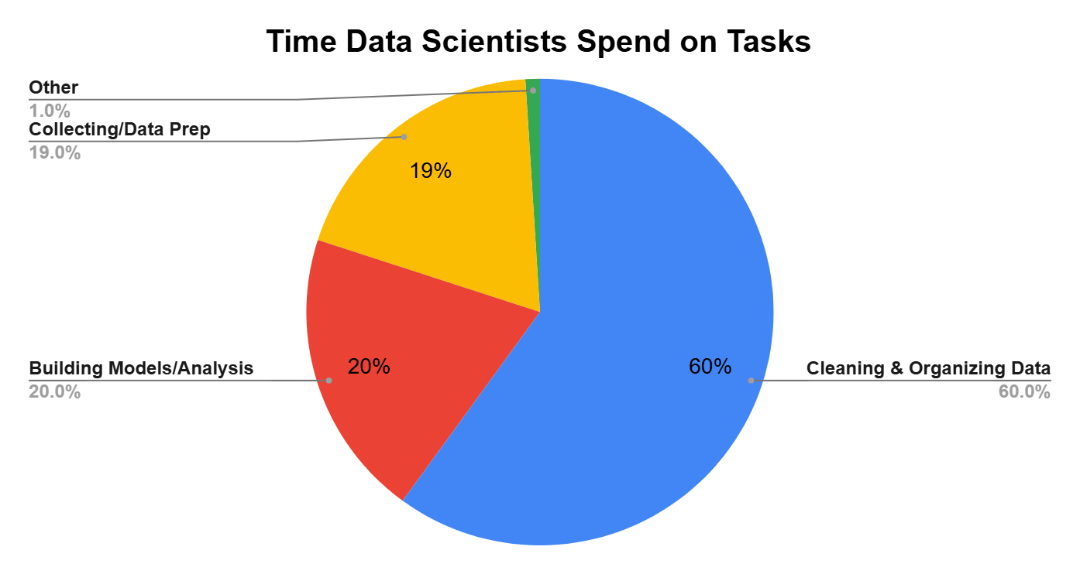
Source: CrowdFlower Data Scientist Survey, 2025
Step-by-Step Guide to Data Quality Assessments
Remark for Data Quality Assessment:
Keep the assessment focused and outcome-driven. Avoid unnecessary complexity that increases effort without improving decisions or reducing risk. Concentrate on the real bottlenecks in your delivery process where data accuracy, completeness, or timeliness has the most significant business impact and therefore truly deserves deeper evaluation. A well-scoped, targeted review delivers more actionable insights and faster improvements than an overly broad analysis.
Step 1. Choosing the Right Indicators
Indicators are critical benchmarks for assessing data quality, directing the focus to areas that significantly impact overall data quality. Selecting appropriate indicators helps identify specific data quality issues, providing a clear path for improvement. Effective indicators align with organizational goals, ensuring that the assessment process is both relevant and actionable.
Criteria for Selecting Indicators
Select indicators that align with business objectives and provide actionable insights. Key indicators include accuracy, completeness, consistency, timeliness, and validity. These indicators target essential data quality dimensions, ensuring precise improvements. Also, consider the following:
-
Relevance: Ensure indicators reflect the specific needs and objectives of the organization.
-
Feasibility: Indicators should be practical to measure with available resources and tools.
-
Comparability: Choose indicators that allow for benchmarking against industry standards or historical data.
Importance of Relevant Indicators
Relevant indicators provide targeted insights that drive specific improvements, enhancing decision-making and operational efficiency. Aligning indicators with strategic goals ensures the assessment yields valuable and actionable results. Using relevant indicators also helps in prioritizing data quality initiatives and allocating resources effectively.
As an example, in product data these indicators can be those, which are commonly across the delivery stream. The attributes could be like:
-
Product code
-
Product revision
-
Description
-
Technical specification
-
Weight
-
Unit of measure
-
Classification
Generally, common information which is critical for the function of design, procurement, manufacturing, logistics and service.
In modern data environments, indicator selection should also reflect automation and downstream usage. Data feeding dashboards, APIs, or machine learning models typically requires stricter thresholds than data used for exploratory analysis. Indicators should therefore be reviewed regularly as data consumers and use cases evolve.
Step 2. Reviewing Existing Data and Preparing for Field Activities
Reviewing existing data and preparing for new data collection are foundational steps in data quality assessment. This process ensures a comprehensive understanding of current data quality and identifies gaps needing attention. Preparing for field activities involves planning methodologies that align with quality standards, ensuring the reliability of newly collected data.
Analyzing Existing Documents
Examine historical records, reports, and logs to identify initial quality issues. This analysis helps understand the context and current state of the data, guiding further assessment. Important aspects to consider include:
-
Data Sources: Identify all sources of data to understand their relevance and reliability.
-
Data Usage: Analyze how the data has been used in decision-making processes to gauge its impact.
Reviewing Available Datasets
Evaluate existing datasets for quality issues like missing values, duplicates, or inconsistencies. Early identification of these problems aids in prioritizing assessment activities and ensures efficient use of resources. Key actions include:
-
Data Profiling: Use profiling tools to get an overview of the data’s condition.
-
Metadata Review: Examine metadata to understand the structure, constraints, and relationships within the data.
Planning Field Activities
Design methodologies for new data collection to address gaps in existing data. Create surveys, interview protocols, or automated data collection systems adhering to strict quality standards, ensuring reliable and consistent new data. Consider the following:
-
Sampling Methods: Ensure samples are representative of the population to avoid bias.
-
Data Collection Tools: Choose appropriate tools and technologies for accurate data capture.
-
Training: Ensure that field staff is well-trained in data collection procedures to maintain consistency and accuracy.
Step 3. Evaluating Data Collection and Management Systems
Evaluating data collection and management systems is essential for maintaining data integrity throughout the organization. This step involves a thorough analysis of technical configurations and procedural workflows to ensure they support high-quality data management. Proper evaluation helps identify weaknesses in current systems and provides a basis for implementing improvements.
System Analysis
Analyze data management systems to verify data validation rules, backup protocols, and configurations that prevent data loss and corruption. For instance, ensure a CRM system validates email formats correctly to reduce errors. Additional considerations include:
-
System Integration: Ensure systems can integrate seamlessly with other data sources.
-
Scalability: Verify that systems can handle increased data volumes as the organization grows.
-
Security: Assess data security measures to protect against unauthorized access and breaches.
Process Evaluation
Evaluate data management processes to identify improvement and optimization areas. Assess data entry procedures, data flow processes, and integration methods. Streamlining these processes reduces errors and enhances data quality, such as implementing automated data entry validation to minimize human error. Key aspects include:
-
Workflow Analysis: Map out data workflows to identify bottlenecks and inefficiencies.
-
Compliance Checks: Ensure processes comply with relevant regulations and standards.
Tool Assessment
Evaluate the effectiveness of tools used in data collection and management. Assess their efficiency in handling data, detecting errors, and supporting data validation. TikeanDQ offers practical features for managing data quality, from assessment to implementation, including advanced features for data profiling, verification, and validation.
Modern ETL and ELT tools can automate data validation and standardization at scale, but they do not eliminate the need for clear rules, ownership, and monitoring. Automation amplifies both good and bad practices, making governance and design choices even more critical.These tools automate the process of gathering data from different sources, cleaning and organizing it, and then storing it in a database. Additional factors to consider:
-
Usability: Ensure tools are user-friendly and meet the needs of the data management team.
-
Support and Maintenance: Check for vendor support and tool maintenance services.
-
Cost-Benefit Analysis: Evaluate the cost-effectiveness of tools relative to their benefits in maintaining data quality.
Step 4. Assessing Implementation and Operationalization
Assessing implementation and operationalization verifies that data quality measures are effectively integrated into daily operations. This step evaluates the execution of data quality initiatives and their impact on organizational processes, ensuring that planned improvements are realized and sustained.
Reviewing Implementation
Review the steps taken to implement data quality measures. This includes:
-
Adherence to Plan: Check if the implementation followed the initial plan without deviations.
-
Resource Utilization: Assess whether resources (time, budget, personnel) were used efficiently.
-
Challenges and Resolutions: Identify any challenges faced during implementation and how they were addressed. This helps in understanding what adjustments may be necessary.
Operational Performance
Evaluate the performance of data quality measures in real-time operational settings. This involves:
-
Effectiveness: Measure how well the data quality measures are working in practice.
-
Efficiency: Assess the impact on operational processes, such as speed and accuracy of data handling.
-
Sustainability: Determine if the improvements are sustainable over the long term, ensuring that quality is maintained without additional effort.
Field Observations
Conduct field observations to gather qualitative data on the application of data quality measures. This includes:
-
Interviews and Surveys: Collect feedback from staff involved in data processes to understand their experiences and challenges.
-
Process Observation: Directly observe data handling processes to identify practical issues.
-
Practical Challenges: Identify any practical challenges faced by staff and gather insights into areas needing further support.
Step 5. Verifying and Validating Data
Verifying and validating data ensures that it is accurate, reliable, and meets predefined quality standards. This step uses various techniques to confirm that the data is suitable for its intended use, crucial for maintaining data integrity.
Data Verification Techniques
Data verification techniques confirm the accuracy and consistency of data. These include:
-
Cross-checking: Comparing data against trusted sources to verify its accuracy.
-
Duplicate Checks: Identifying and eliminating duplicate entries to ensure data uniqueness.
-
Validation Rules: Applying predefined rules to check data entries for conformity with expected patterns and formats.
Validation Procedures
Validation procedures ensure data adheres to business rules and standards. This involves:
-
Automated Checks: Setting up automated systems to validate data formats, values, and logical consistency.
-
Manual Reviews: Conducting periodic manual reviews to catch issues that automated systems might miss.
-
Compliance Verification: Ensuring data meets regulatory and compliance standards, is critical for industries with strict regulatory requirements.
Anomaly Detection Methods
Anomaly detection methods identify unusual patterns or outliers in the data that may indicate quality issues. These include:
-
Statistical Techniques: Using statistical methods to find anomalies that deviate significantly from the norm.
-
Machine Learning Models: Employing machine learning to detect complex patterns that traditional methods might miss.
-
Root Cause Analysis: Investigating and addressing the underlying causes of detected anomalies to prevent recurrence.
Verification and validation should not be treated as one-time controls. In fast-changing data pipelines, rules that were correct six months ago may silently become obsolete. Regular review of validation logic is essential to prevent outdated checks from masking emerging quality issues.
Step 6. Compiling the Data Quality Assessment Report
Compiling the data quality assessment report is the final step, summarizing the findings and providing actionable recommendations. This comprehensive document communicates the results of the assessment to stakeholders, helping to drive data quality improvements.
Executive Summary
The executive summary provides a high-level overview of the assessment, designed for senior management and stakeholders. It includes:
-
Overview of Findings: Summarize the main issues discovered during the assessment.
-
Impact Analysis: Briefly describe the impact of data quality issues on the organization.
-
Top Recommendations: List the most critical recommendations for improvement.
Detailed Findings
Present detailed findings of the data quality assessment, including identified issues, their impacts, and root causes. This section includes:
-
Issue Identification: Detailed descriptions of each data quality issue identified.
-
Impact Assessment: Analysis of how these issues affect business operations and decision-making.
-
Root Cause Analysis: Examination of the underlying causes of the data quality issues, helping to understand why they occurred.
Actionable Recommendations
Provide actionable recommendations to address the identified data quality issues. These recommendations should be specific and practical, including:
-
Specific Steps: Clearly defined steps for improvement to be taken.
-
Resource Requirements: Outline the resources needed, including time, budget, and personnel.
-
Timeline: Provide a realistic timeline for implementing the recommendations.
-
Monitoring Plan: Suggest methods for monitoring the effectiveness of the improvements, ensuring that they lead to sustained data quality.
Key Considerations in Data Quality Assessments
Data Checklists
Data quality checklists are essential tools that guide the assessment process, ensuring no critical quality aspect is overlooked.
Verifying accuracy involves ensuring data accurately reflects real-world scenarios and is free from errors. This can be achieved through cross-checking data against authoritative sources to validate accuracy and using error detection algorithms to identify and correct data entry errors.
Completeness verification ensures all required data is captured by employing data profiling tools to identify missing or incomplete data and conducting gap analysis to compare existing data against required data.
Consistency verification ensures data remains uniform across all sources by comparing data across different systems through data reconciliation and implementing validation rules to enforce consistency across datasets.
Data Pipelines Checklist
Maintaining data integrity through the entire pipeline from collection to consumption is crucial for ensuring high-quality data.
Regular checks are essential to maintain the integrity of the data throughout its lifecycle, including implementing validation checks at each stage of the data pipeline and using database integrity constraints.
Ensuring consistent processing across systems prevents errors introduced during data transformations by setting up automated validation rules and maintaining audit trails to track data changes and transformations.
Continuous monitoring and routine maintenance are critical for the long-term health of data pipelines, utilizing monitoring tools to oversee data flow and detect anomalies, and conducting regular audits to ensure the pipeline is functioning correctly.
Roles and Responsibilities in DQAs
Defining clear roles and responsibilities is key to a successful Data Quality Assessment (DQA).
Data stewards manage and oversee the quality of data within an organization. They ensure data policies and standards are followed, continuously monitor data quality, and address issues.
Data governance teams set policies and standards that define how data should be handled and protected, developing and maintaining the data quality framework and ensuring compliance with regulatory and organizational standards.
Quality assurance (QA) teams are responsible for the ongoing assessment and improvement of data quality, conducting regular audits to assess data quality, and implementing quality improvement initiatives to enhance data quality.
Common Pitfalls, Challenges, and Limitations in Data Quality Assessment
Even well-designed Data Quality Assessments face practical challenges that can reduce their effectiveness if not addressed early. Understanding these pitfalls helps organizations plan realistic assessments, avoid wasted effort, and design mitigation strategies that fit real-world constraints rather than ideal conditions.
Resource Constraints and Limited Ownership
One of the most common challenges in DQAs is limited availability of time, budget, and skilled personnel. Data quality work is often added on top of existing responsibilities, with no dedicated owners or funding. As a result, assessments may be rushed, shallow, or abandoned before meaningful improvements are implemented.
To mitigate this, organizations should scope DQAs carefully and prioritize high-impact data domains. Assign clear data ownership roles, such as data stewards, and focus first on datasets that directly affect revenue, compliance, or operational efficiency. A smaller, well-executed assessment delivers more value than a broad but under-resourced one.
Conflicting Data Sources and System Discrepancies
Many organizations store the same data across multiple systems, such as ERP, CRM, spreadsheets, and data warehouses. These sources often conflict due to different update cycles, validation rules, or ownership models. This creates confusion about which source is authoritative and undermines trust in assessment results.
A practical approach is to define a clear “system of record” for each data domain before starting the assessment. Data reconciliation rules should be documented and applied consistently. Where conflicts cannot be eliminated, transparency is critical. The DQA report should clearly document discrepancies and explain their business impact.
Data Silos and Poor System Integration
Data silos are a major limitation in enterprise environments. When systems are poorly integrated, assessments only capture partial views of data quality. Issues that occur during handoffs between systems often remain invisible, even though they may have the largest operational impact.
To address this, DQAs should include pipeline level assessments rather than focusing only on static datasets. Mapping data flows across systems helps identify where errors are introduced. Incremental integration, shared metadata repositories, and standardized interfaces improve visibility and reduce long-term quality risks.
Evolving Data Semantics and Business Definitions
Data meanings change over time as business models, regulations, and reporting requirements evolve. Fields that were once clearly defined may gradually drift in meaning, leading to inconsistent interpretation and misuse. This semantic drift is difficult to detect through technical checks alone.
Mitigation requires strong metadata management and governance practices. Business definitions should be documented, reviewed regularly, and versioned when changes occur. DQAs should validate not only data values but also whether fields are still being used according to their intended definitions.
Overreliance on Tools Without Process Alignment
Advanced data quality tools can profile, validate, and cleanse data at scale, but they do not replace sound processes. Organizations often assume that tool deployment alone will fix data quality problems, without addressing upstream causes such as poor data entry practices or unclear accountability.
Effective mitigation involves aligning tools with operational workflows. Validation rules should be embedded at data entry points, and feedback loops should exist so users understand and correct errors. Tools should support processes, not operate in isolation.
Resistance to Change and Organizational Friction
Data quality initiatives often surface uncomfortable truths about processes, performance, or accountability. Teams may resist findings, dispute metrics, or deprioritize remediation work. This organizational friction can stall improvements even when assessment results are clear.
To reduce resistance, DQAs should focus on business impact rather than technical blame. Present findings in terms of risk, cost, and opportunity. Involving stakeholders early and sharing quick wins helps build trust and momentum for long-term improvements.
Overemphasis on Perfection Over Value
A common but often unspoken limitation of DQAs is the pursuit of perfect data quality. Attempting to eliminate every error can delay delivery and reduce trust in the assessment process. Mature organizations define acceptable quality thresholds based on business impact, focusing remediation where poor data creates measurable risk rather than theoretical flaws.
Conclusion
Maintaining a data-driven culture requires that Data Quality Assessment (DQA) be recognized as an important part of the process. It involves using rigorous techniques, following standards, and taking methodical steps to ensure data is reliable and valuable.
Organizations that adopt these practices can better use their data for strategic insights, operational improvements, and gaining a competitive edge. Quality data helps navigate today’s business challenges, leading to innovation and efficiency.
High-quality data does not happen by accident. It is the result of deliberate assessment, clear ownership, and continuous prioritization. Organizations that treat Data Quality Assessment as an ongoing capability rather than a one-time exercise are best positioned to scale analytics, automation, and AI with confidence.
FAQ
How do I select the right indicators for Data Quality Assessments (DQAs)?
Choose indicators reflecting accuracy, completeness, and reliability. Align them with your assessment objectives and decision-maker needs. Use tailored tools and consult experts for robust selection criteria. Key metrics should reflect the specific objectives of your data quality assessment and the needs of decision-makers. Start by selecting e.g. 10 attributes per data domain / dimension, common across various functions in your organization.
What are the steps involved in the implementation of a data management system?
The process involves preparatory, field, and verification phases. Configure the system to meet governance requirements, normalize data, and conduct verification exercises to ensure data integrity. Involve data engineers and DQA experts. Ensure the system is configured to meet governance requirements and conduct thorough verification exercises.
How can verification and validation improve data quality?
Verification checks data against documents and standards, identifying errors. Validation ensures data conforms to expected formats and structures, enhancing validity. Both steps maintain strengths and address weaknesses in the data set. These steps are essential for maintaining data quality and addressing data inconsistencies.
What should be included in a comprehensive DQA report?
Include an executive summary, detailed findings, and actionable recommendations. Cover strengths and weaknesses, tools and methods used, and compliance impact. Visualizations help communicate complex insights effectively. Highlight the impact on governance compliance and use visualizations for clarity.